JS 基础:闭包
函数内部的函数:私有函数
首先,我们从这个内部函数去说开,因为这个是形式上的,如果一开始讲作用域,有点故意。闭包在形式上就是函数内部的函数,比如:
function add(a) {
return function (b) {
return a + b;
};
}
var c = add(5)(10);这是一个很奇怪的用法,第一次看到有 function()() 这样的用法?请阅读这篇文章。当执行 add(5) 的时候,返回的结果其实是一个函数,而再执行这个函数,需要再传入一个参数,所以就有了 add(5)(10) 这样的用法。当然,这是一个极端的例子,出现的太早,我们来看下最常见的一种用法吧。
jQuery(function ($) {
function message(msg) {
alert(msg);
}
if ($(window).width() > 1000) message('window宽度大于1000');
});如果你用 jquery,这段代码应该经常使用吧。如果你仔细去观察就会发现,第一个 function 被作为参数,传给了 jQuery() 这个函数,而在 function 内,又有一个 message() 函数。所有的 jQuery 代码被放在第一个 function 中去处理。第二个函数就是函数体内部的函数,这个函数在函数体内声明,一旦外层函数执行完毕,那么这个函数就失去了作用,在 jQuery() 外无法使用 message(),因此,message() 是第一个函数内部的私有函数。
变量的作用域
函数内部的变量有两种,一种是局部变量,一种是全局变量。局部变量只在当前函数体内有效,出了函数体,就回到全局变量的范围,局部变量无效。
var age = 10;
function a(age) {
return age + 1;
}
function b(_age) {
return age + _age;
}
function c(_age) {
var age = 11;
function add() {
return age + _age;
}
return add();
}
alert(a(9)); // 10 : 9 + 1
alert(b(2)); // 12 : 10 + 2
alert(c(5)); // 16 : 11 + 5在上面的代码中,我们看 b 和 c 函数。b 函数中的 age 直接引用了全局变量 age(10),而 c 函数中重新声明了局部变量 age,因此,全局变量 age 在 c 函数中无效。
但是在 c 中,函数内部有一个函数 add(),它的函数体内的 age 是指 c 中声明的局部变量,而非全局变量 age。从这个例子里,反映出了变量的作用域,函数内的函数体里,如果没有声明局部变量,就会承认其父级甚至祖先级函数的变量,以及全局变量。
闭包
怎么样才算是一个闭包呢?我们来看下面的代码:
function a() {
var age = 10;
return function () {
return age;
};
}
var age = a();
alert(age()); // 10按照我们前面说的作用域,在上面这段代码中 age 是 a() 的局部变量,按道理出了函数就不能被访问了。但是,a() 返回了一个私有函数,个这个函数返回了 age,这导致我们可以在 a() 外部,仍然可以访问到本来是局部变量的 age,这个时候,我们就把这个内部函数称为闭包。它的原理就是函数内部的函数可以访问父函数的局部变量。
综合上面的阐述,我们要这样去理解闭包:
- 闭包是一个函数,它使用了自己之外的变量。
- 闭包是一个作用域。
- 闭包是“由函数和与其相关的引用环境组合而成的实体”。
- 严格的讲,闭包常常表现为一个函数内部的函数,它使用了非自己定义的、自己所在作用域内的变量,并且使这些变量突破了作用域的限制。
所以,我们文章最开头的那段代码,也有一个闭包。
一个典型的闭包:
- 函数内的函数
- 这个内部函数引用了父函数的局部变量
- 这个内部函数使引用的变量突破了作用域限制
var a = 1;
function fun() {
return a + 1;
}
alert(fun());这也可以算作一个闭包,a()引用了它之外定义的变量。但是这不算严格的闭包,因为它没有在突破作用域的这个点上表现出来。
var a = 1;
function fun() {
var b = 2;
return function () {
return a + ++b;
};
}
var c = fun();
alert(c()); // 4
alert(c()); // 5这就是一个非常典型的闭包了。而且为什么 alert(c()) 两次的值不同,我们还会在下面解释到。
为了让你更加明晰的和你曾经开发过的案例联系在一起,我们来看我们曾经做过的这样的事:
define(function () {
var age = 10;
function getAge() {
return age;
}
function grow() {
age++;
}
return {
age: getAge,
grow: grow,
};
});这是我们在 require.js 中的一种写法,把它还原为我们熟悉的闭包模式:
function Cat() {
var age = 10;
function getAge() {
return age;
}
function grow() {
age++;
}
return {
ageAge: getAge,
grow: grow,
};
}
var cat = Cat();
var age = cat.getAge();
alert(age); // 10
cat.grow();
age = cat.getAge();
alert(age); // 11从内存看闭包
现在,我们就要来解释为什么上面的 alert() 两次的结果不同的原因了。
首先,我们来看下普通的函数声明和使用过程中内存的变化:
function fun(a, b) {
return a + b;
}
alert(fun(1, 2));
alert(fun(3, 4));上面是我们没有遇到闭包的情况,内存我们这样来画(注意,我这里只是抽象的画出内存变化,而不是真实的 javascript 内存机制。)
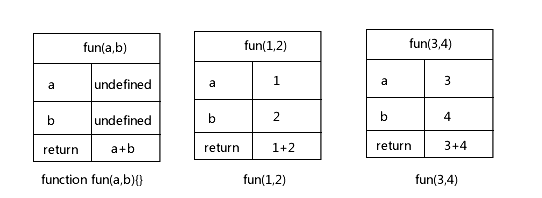
在每一次执行完 fun() 之后,fun()函数的执行环境被释放(回收机制)。
接下来我们来看一个闭包:
function fun(a) {
return function (b) {
return a + b;
};
}
var add = fun(2);
alert(add(2));
alert(add(4));上面就出现闭包了,注意,我们这里出现了一个 add 变量。
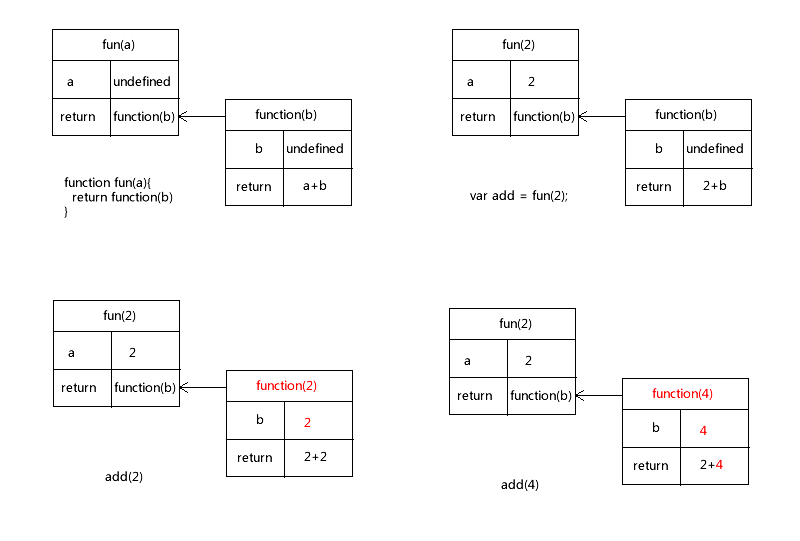
在后两步中,实际上 fun(2) 部分没有任何变化,所变的,则是在内部函数所对应的内存区域中有变化。细心的你,可能会发现这里面的问题所在,当执行完 add(2) 之后,fun 对应的内存没有被释放掉,而它的内部函数,也就是 function(2) 被释放掉了,在执行 add(4) 的时候,仅仅重新运行了内部函数。如果连 fun() 对应的内存出现了变化怎么办?我们来看下面的例子:
function fun() {
var b = 2;
return function (a) {
return a + ++b;
};
}
var c = fun();
alert(c(1)); // 4
alert(c(1)); // 5注意,这可是个非常典型的闭包的例子,它有一个局部变量 b,我们来看它的内存图。
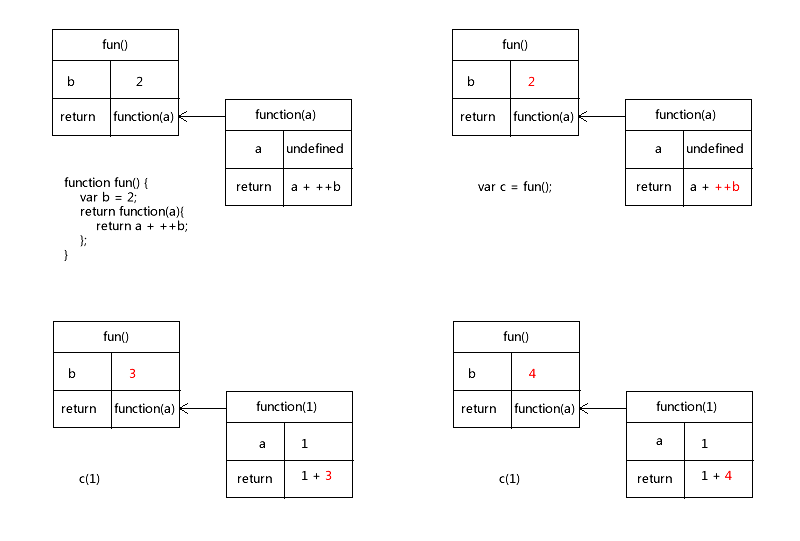
注意第 2、3、4 步中内存的变化。第 2 步时,我们仅仅将 fun() 赋给变量 c,这个时候,内部函数 function(a) 并没有被执行,所以 ++b 也没有被执行,b 的值还是 2。但是第 3 步开始,++b 被先执行,++b 的意思是先自加,再进行运算,和 b++ 是不同的,如果是 b++,虽然 c(1) 的最终结果还是为 4,但是在 c(1) 执行开始时,b 应该为 2,执行完之后才是 3。
奇妙的事情发生了,在内部函数中,++b 导致了局部变量值发生了变化,b 从 2 变成了 3,而且,内存并没有被释放,fun() 的执行环境没有被销毁,b 还被保存在内存中。到第 4 步时,b 的初始值是 3,经过 ++b 之后,变成了 4。
这个内存分析非常形象的把闭包概念中,关于“突破作用域限制”这个点描述的非常清楚,原本按照作用域的限制,函数的局部变量不能被外部环境访问,更不能被修改,但是闭包却使得外部环境不仅可以读取到局部变量的内容,甚至可以修改它,深入一点就是:闭包会导致闭包函数所涉及到的非自身定义的变量一直保存在内存中,包括其父函数在内的相关环境都不会被销毁。
闭包到底有什么用
说了这么多,那闭包到底有什么用,我们为什么要使用闭包呢?从上面的阐述中,你应该已经知道了闭包的唯一作用:突破作用域限制。那如何使用这个作用为程序服务呢?
常驻内存,意味着读取速度快,(当然,内存花销也大,导致内存溢出)。常驻内存,意味着一旦初始化以后,就可以反复使用同一个内存中的某个对象,而无需再次运行程序。而这一点,是很多插件、模块的设计思想。
最好的例子就是上文我举得那个 define() 的例子,后面用我们今天所了解的形式去实践之后,你就会发现原来可以把 function 当做一个其他语言中的 class 来对待,cat.getAge(), cat.grow() 这样的操作是不是很符合我们在编程中的使用习惯呢?一旦一个产生之后,这个 cat 就一直在内存中,随时可以拿出来就用,它就是一个实例化对象。
为了更形象,我们来创建一个简单的代码块:
function Animal() {
this.age = 1;
this.weight = 10;
return {
getAge: function () {
return this.age;
},
getWeight: function () {
return this.weight;
},
grow: function () {
this.age++;
this.weight = this.age * 10 * 0.8;
},
};
}
function Cat() {
var cat = new Animal(); // 继承
cat.grow = function () {
cat.age++;
cat.weight = cat.age * 10 * 0.6;
};
return cat;
}
var cat1 = new Cat();
alert(cat1.getAge());
cat1.grow();
alert(cat1.getAge());为什么要举这个例子呢,因为我想让你想象这样一种场景,如果没有闭包怎么办?
没有闭包是这样的一种状态:函数无法访问自己父级(祖先,全局)对象的变量。比如:
var a = 1;
function add() {
return ++a; // 如果没有闭包机制,会undefined报错
}这种情况怎么办?必须以参数的形式传入到函数中:
var a = 1;
function add(a) {
return ++a;
}
alert(add(a)); // 2如果是这样,就很麻烦了,你需要在每一个函数中传入变量。而更麻烦的是,没有了作用域的突破,例如:
function Cat() {
age = 1;
function getAge(age) {
return age;
}
function grow(age) {
age++;
}
return {
getAge: getAge,
grow: grow,
};
}
var cat = new Cat();
cat.grow();
alert(cat.getAge()); // 1,没有被修改这种情况下,我们无论如何都无法使用这种办法来实现我们的目的。唯一能够实现的,就是按照下面这种方法:
var cat = {
age: 1,
weight: 10,
grow: function () {
this.age++;
this.weight += 3;
},
};
var cat1 = cat;
alert(cat1.age);
cat1.grow();
alert(cat1.age);我们聪明的使用到了 this 关键字,但是这样一个坏处是,age, weight 这些属性直接暴露给外部,我们只需要执行 cat1.age = 12; 就可以马上让 cat 长到 12 岁,而体重却没任何变化。
总结而言,闭包可以带来这么几个方面的应用优势:
- 常驻内存,加快运行速度
- 封装
闭包使用中的注意点
除了上面提到的内存开销问题外,还有一个需要被注意的地方,就是闭包所引用的外部变量,在一些特殊情况下会存在与期望值不同的误差。
function init() {
var pAry = document.getElementsByTagName('p');
for (var i = 0; i < pAry.length; i++) {
pAry[i].i = i;
pAry[i].onclick = function () {
alert(this.i);
};
}
}在上面这段代码中,你希望通过一个循环,来为每一个 p 标签绑定一个 click 事件,然而不幸的是,for 循环中使用的闭包函数没有让你如愿以偿,在闭包函数中,i 被认作 pAry.length,也就是循环到最后 i 的最终值。为什么会这样呢? 原来,闭包引用变量,而非直接使用变量,“引用”的意思是将指针指向变量的内容。由于这个原因,当 i=0 的时候,闭包里面的 i 确实是 0,但是当随着 i 的值变大的时候,闭包内的 i 并没有保存当前值,而是继续把指针指向 i 的内容,当你点击某个 p 标签的时候,i 的内容实际上是 for 到最后 i 的值。
同样,这个问题会出现在 setTimeout,setInterval,\$.ajax 等这类操作中,你只要记住,当你绑定操作时,和执行操作时,对应的变量是否已经变化就 OK 了。